
The New AI Layer in Software Architecture: LLMs, RAG, Agents, and MCP Explained for Real-World Engineers
Part 1 — Architectural Patterns for Generative AI (SEArt Series)

Every few years, something arrives that forces us to rethink the way we design systems.
Microservices changed how we structure complexity.
Event-driven architecture changed how we communicate.
Cloud changed how we deliver and scale.
And now AI is disrupting—again—but with far more noise, confusion, and buzzwords than any shift we’ve seen before.
LLMs.
RAG.
Agents.
Guardrails.
MCP.
Vector DBs.
Tool-use.
Everyone talks about these things, but very few explain how they actually fit into a real software architecture—not a demo, not a toy notebook, but a true system with bounded contexts, SLAs, budgets, observability, failure modes, and users who will complain when something breaks at the worst possible time.
This post aims to do just that:
Give you a mental map of the AI layer from the perspective of a software architect.
No hype. No magic. No unicorn dust.
Just architecture.
Let’s dive in.
LLMs: A New Probabilistic Component in Our Architecture
A Large Language Model isn’t magic.
From an architectural perspective:
An LLM is a probabilistic function with expensive inference and unpredictable output.
It does reasoning.
But not like a rules engine.
Not like code.
And definitely not like a deterministic microservice.
This is why you don’t put an LLM inside your core workflows.
Instead, you isolate it behind:
an LLM Gateway (OpenAI, Bedrock, Vertex AI, etc.)
a Prompt Library
safety filters
rate limits
logging/observability
The LLM layer becomes a boundary, not a dependency.
RAG: The Pattern That Gives LLMs Real Knowledge
LLMs know a lot… about the public internet.
But they don’t know your domain:
your internal APIs
your codebase
your architecture
your business rules
your documentation
your support tickets
your catalog
your incidents
That’s where Retrieval-Augmented Generation (RAG) comes in.
RAG enriches the model with context retrieved from your knowledge sources.
The architecture consists of:
Embedder — converts text into vectors
Vector Database — stores embeddings (Pinecone, Weaviate, Qdrant)
Retriever — finds the most relevant pieces at runtime
LLM — uses retrieved knowledge to generate grounded answers
RAG is not “just” a technique—it’s a full architectural pattern of knowledge retrieval.
Agentic Patterns: When the LLM Doesn’t Just Answer… It Acts
RAG gives an LLM memory.
Agents give an LLM capabilities.
An agent is:
An LLM that can choose tools and perform actions autonomously within defined boundaries.
Tools can be:
APIs
functions
calculations
database queries
workflow steps
MCP tools
Agents can:
take multiple steps
plan
decide
execute tasks
correct themselves
This is powerful—and dangerous—if not constrained.
Good agents behave like smart assistants.
Bad agents behave like unsupervised interns with admin privileges.
Agents are a full architectural pattern: autonomous reasoning with tool execution.
MCP: The Enabler That Makes Tool-Use and Agentic Workflows Actually Scalable
There’s a piece of this whole story that isn’t an architectural pattern by itself, but has quickly become one of the most important enablers in modern AI systems:
MCP — Model Context Protocol.
If LLMs are the reasoning layer,
and RAG is the memory layer,
and agents are the autonomy layer,
MCP is the interface layer — the part that allows models and agents to interact with real systems in a standardized, safe and introspectable way.
Before MCP, integrating tools into an LLM or an agent was fragile and inconsistent:
Each provider (OpenAI, Anthropic, local models) had its own API format.
Tool definitions lived inside prompts (yes, really).
Schema mismatches caused silent failures.
There was no discovery mechanism: you had to “tell” the model what it could do.
Tool-use was tightly coupled to specific model vendors.
Security controls were improvised and scattered.
MCP changes this dynamic completely.
It introduces a unified contract describing:
what tools exist
what actions they expose
what parameters they require
what schemas they follow
what capabilities are allowed
With this, an LLM or an agent can discover tools, understand their structure, and use them safely — without relying on brittle prompt instructions.
In other words:
MCP is not an architecture pattern — it’s the enabler that makes agentic systems, tool-use, automation and safe AI orchestration actually viable.
It becomes a clean, vendor-independent bridge between:
your microservices
your automations
your data sources
your business actions
and the AI layer
A Real Use Case Where I Applied MCP (High-Level View)
To make this more tangible, here’s a simplified real scenario I implemented.
Imagine a user asks the system:
“Send the list of payments due today to Charles Sant.”
An LLM alone cannot perform this task — it needs real system capabilities.
Through MCP, the LLM can:
discover which tools exist
inspect their schemas
call the right tool with structured data
use the result to perform a follow-up action
The diagram below shows a high-level view of how this actually works end-to-end:
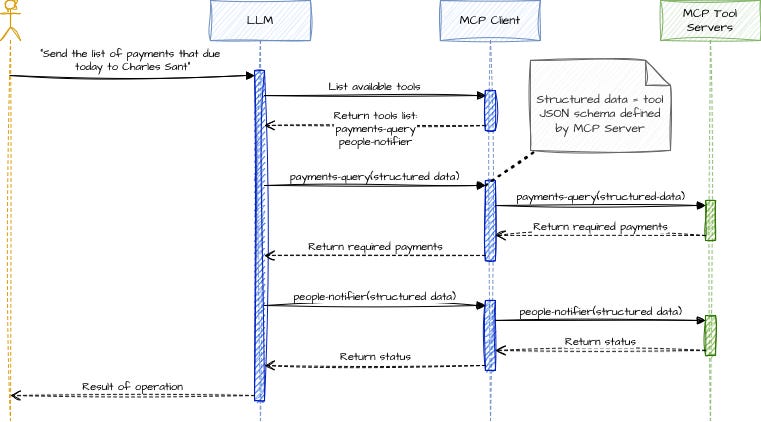
This flow represents how an LLM, an MCP Client, and multiple MCP Tool Servers coordinate to fulfill a real user request:
1. The LLM discovers available tools
It doesn’t “guess” or rely on a prompt description.
It asks the MCP Client:
“What tools do I have?”
The MCP Client replies:payments-querypeople-notifier
These tools are introspectable because MCP provides structured schemas.
2. The LLM chooses the right tool based on schema
It selects payments-query first, sending structured data (JSON compliant with the tool’s schema).
The MCP Client calls the appropriate MCP Tool Server, which returns the required payments.
3. The LLM composes a second action
Now that it has the list of payments, it prepares a second structured request:
a call to
people-notifier
Again, the MCP Client relays the request, and the MCP Tool Server returns the execution status.
4. The LLM returns the final result to the user
All tool interactions are chained through the MCP Client, keeping:
your microservices safe
your API surface clean
your tool definitions standardized
your agentic workflow predictable
Additional Tips for Real-World AI Architecture
Before closing, here are a few high-impact recommendations that can help you design AI-enabled systems that remain safe, predictable and maintainable as they grow:
1. Always validate input and output
LLMs produce probabilistic output, not guaranteed structure.
Add lightweight validation to avoid malformed requests reaching your internal systems.
2. Version everything
Prompts, embeddings, RAG pipelines, tool schemas, agent behaviors.
Treat these assets like code — because they are.
3. Keep agents narrow and supervised
A “general-purpose agent” is a nice idea, but in practice, small task-specific agents with well-defined tools behave far better.
4. Apply caching everywhere
Embedding cache, retrieval cache, and generation cache reduce latency and cost dramatically.
5. Don’t forget security
AI introduces new attack surfaces.
Instead of going deep here, I’ll simply recommend this:
study the OWASP Top 10 for LLM Applications when designing any generative AI feature.
It provides practical guidance for avoiding prompt injection, unsafe tool execution, and other real-world risks.
(You don’t need to memorize every item—but awareness goes a long way.)
6. Separate deterministic logic from AI logic
Critical flows should not depend entirely on an LLM.
Build fallbacks, guardrails, and human-in-the-loop paths for sensitive operations.
7. Measure what your AI layer is actually doing
Logging tool calls, recording decisions, tracking latency and cost — this turns the AI layer from a “black box” into something observable.
These small practices compound over time and make a massive difference in production.
Conclusion
This was a high-level introduction to how LLMs, RAG, agents, and MCP fit together into a modern software architecture.
My goal wasn’t to go deep on every topic, but to give you a mental map that helps you reason about the AI layer with clarity — without hype, magic, or hand-waving.
If this topic interests you, stay tuned.
The next posts in this series will go deeper into individual patterns, starting with Guardrails, and I’d love for you to join the discussion, share your experiences, and challenge the ideas here.
Thanks for reading — and let’s keep building better systems together.
Hey, great read as always. You really nail the fundamental shift required in thinking about LLMs as a probabilistic component rather than a deterministic service, which is a crucial architectural insight. While the isolation of these models is clearly essential, I find myself thinking about how we design user experiences that truly embrace and effectively manage the inherent unpredictability of such probabilistic ouputs.