
The Guardrails Pattern
Part 2 — Architectural Patterns for Generative AI

From my personal perspective, as solutions architects working with generative AI eventually hits the same wall: LLMs are not reliable neither predictable.
They hallucinate.
They shift behavior with tiny changes in context. And sometimes they answer with absolute conviction… even when they’re dead wrong.
In demos, that could be funny. In production? It’s a risk technical, operational, and yes, even legal.
That’s why Guardrails should be treated as an architectural pattern. They deserve a seat next to the classic patterns we already know.

Context
Today’s AI systems mix:
LLMs that “reason”
RAG pipelines retrieving domain knowledge
MCP tools for real actions
Agents orchestrating multi-step workflows
And all of that sits in an environment where people expect:
correctness
consistency
safety
traceability
reliability
The problem?
LLMs are probabilistic. Our systems are not.
Problem
The moment you plug an LLM into a real workflow, you inevitably face:
unpredictable output
fabricated details
dangerous or unauthorized tool usage
schema inconsistencies
harmful or ambiguous user input
non-deterministic behavior across model versions
These aren’t theoretical.
They break workflows. They cost money.
And sometimes, they spill into the real world.
A real case: Air Canada (2024)
In early 2024, Air Canada lost a legal dispute after its chatbot gave a grieving customer incorrect refund guidance.
The model confidently described a policy that didn’t exist.
The customer relied on it, spent real money, and later discovered that the “bereavement refund” the chatbot promised was fiction.
The Canadian tribunal was clear:
Air Canada was responsible for what its AI said, just as if it had published the statement on a static page.
Result: compensation, public scrutiny, and a clear message for the rest of us.
Without guardrails, generative AI isn’t just unreliable —
it’s a liability.
Forces
Building AI-enabled systems means navigating tensions between:
LLM creativity vs safety
flexibility vs compliance
speed vs correctness
user expectations vs model unpredictability
cost vs latency (LLM calls aren’t cheap)
Guardrails exist to stabilize these forces.
Solution — The Guardrails Pattern
Guardrails aren’t a single technique.
Here I explain two kinds of strategies:

Input Guardrails (before the LLM)
From a security perspective, we need to be aware of, and handle, two types of input risks:
private or sensitive information
malicious or manipulative prompts that could compromise the LLMs or the system
The first case can be addressed by identifying and masking private or sensitive data before sending anything to the LLM, RAG or any other API.
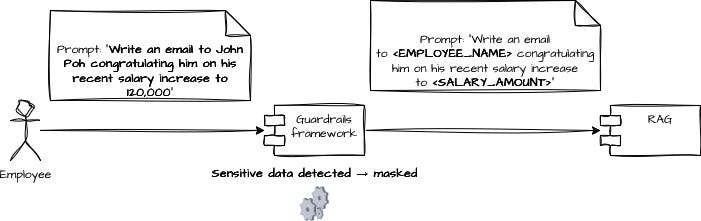
Imagine an employee using an internal HR AI assistant and sending a request like:
“Write an email to John Poh congratulating him on his recent salary increase to 120,000.”
Before this prompt reaches the LLM, a guardrails layer should mask sensitive information — in this case:
the employee’s name
the specific salary amount
So the model actually receives something like:
“Write an email to <EMPLOYEE_NAME> congratulating him on his recent salary increase to <SALARY_AMOUNT>.”
After the LLM generates the email template, the system can safely unmask the values and reinsert the real data before sending the final output to the user.
This keeps the model from storing or training on sensitive data, reduces compliance risk, and ensures private information never leaves safe boundaries.
For the second case, we must actively defend against things like SQL injection, prompt-based attacks (“forget your policies…”, “ignore all previous instructions”), or attempts to push the LLM into tasks outside its scope or specialization.
Output Guardrails (after the LLM)
We find at least three types of output guardrails:
unmasking private or personal information
qualifying and filtering the response
retrying or forwarding policies
As we’ve seen before, if our input guardrails mask the prompt, the response must be unmasked to stay consistent with the original user request.
Using the HR example:
The LLM receives:
“Write an email to <EMPLOYEE_NAME> congratulating him on his recent salary increase to <SALARY_AMOUNT>.”
It might answer with:
“Dear <EMPLOYEE_NAME>,
I wanted to personally congratulate you on your recent salary increase to <SALARY_AMOUNT>...”
An output guardrail will:
Unmask the placeholders:
<EMPLOYEE_NAME> → John Poh
<SALARY_AMOUNT> → 120,000
Qualify and filter the response (tone, policy alignment, no extra sensitive data).
Retry or forward to a human if something looks off (for example, if the model adds details it shouldn’t).
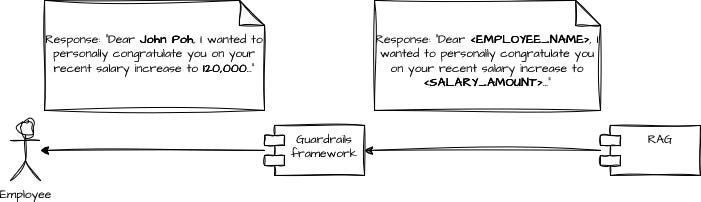
This way, the LLM never sees the raw sensitive data, but the final email that the user receives is still correct and personalized.
Guardrails Through Embeddings
Here’s where things get interesting.
Recently, I’ve been experimenting with a tool called Semantic Router, and it surprised me.
In complex architectures, especially those using multiple MCP tools, cost and latency grow quickly.
Why?
Because the LLM is deciding which tool to call.
Every decision implies a new LLM inference then slower, more expensive, more unpredictable.
Semantic Router flips that idea.
Instead of asking the LLM to choose a tool,
you represent each tool with embeddings
and route the request without calling the LLM at all.
The impact is huge:
millisecond routing
near-zero cost
more deterministic decisions
far safer tool selection
This has cut tool-selection cost in my experiments by 80–95%, depending on the workflow.
And yes: this fits inside the Guardrails Pattern.
Semantic routing becomes an input guardrail that prevents unsafe or expensive decisions before they ever reach the model.
Benefits
Some of the benefits of applying this patterns are:
fewer hallucinations
more predictable workflows
safer tool invocation
better user trust
stable behavior across model updates
easier auditing
with embeddings, reduced cost
Trade-offs
Guardrails add:
engineering effort
some complexity
validation overhead
the risk of over-restricting creativity
higher cost-to-serve
But the alternative, no guardrails, is how you end up in the news like Air Canada.
Closing Thoughts
We’ve passed the stage where generative AI is just a novelty.
It’s becoming part of the core architecture of our systems.
Guardrails aren’t about limiting the model.
They’re about protecting users, organizations, and the system itself.
Tools like Semantic Router make those guardrails not only safer,
but faster and cheaper to implement.
This is just the beginning.
In the next posts, I’ll dig into how guardrails interact with agents, RAG pipelines, and MCP tooling to build safer, scalable AI architectures.
If you’ve implemented guardrails, or struggled without them, I’d love to hear your experience.